Scientometrics Analysis of RStudio applications in PubMed Database
By Reza AA Khoei
October 16, 2022
Introduction
Evaluation and interpretation of scientific productions can be so helpful in determination of prominent authors, active departments and hot topics in a specific field. This process is called scientometrics and bibliometrix. Scientometrics refers to “all quantitative aspects science and scientific research” (Sengupta 1992). On the other hand, Bibliometrics refers to “the application of mathematics and statistical methods to books and other forms of written communication” (Pritchard 1969). Visualization and Statistical methods of these published documents can be analyzed using R bibliometrix package. This package is created and developed by [Massimo Aria] (https://masimoaria.com) and [Corrado Coccurullo] (https://www.corradococcurullo.com).
Our purpose is to investigate the RStudio applications of published scientific papers of PubMed database. In order to, we used bibliometrix package in Rstudio.
Call required packages
First of all we should install and call all of required packages for our analysis.
install.packages("bibliometrix")
install.packages("kableExtra")
install.packages("dplyr")
install.packages("ggplot2")
install.packages("reshape2")
install.packages("pubmedR")options(scipen = 999)
library(bibliometrix)
library(kableExtra)
library(dplyr)
library(ggplot2)
library(reshape2)
library(pubmedR)Search strategy
The search strategy should be considered based on a predefined search text
An API key is required to better and faster searches.Nevertheless, NULL can be put instead of a specific value.
As, RStudio and R programming language are interchangeably used, then both of them are considered in search strategy. After determining the search strategy we searched and finally found 649 documents based on searched terms including articles, book chapters, conference papers and etc.
Now, this data set is necessary to be converted to data frame for statistical analyses. In order to, the following commands are used.
D <- pmApiRequest(query = query, res$total_count, api_key = NULL)## Documents 200 of 649
## Documents 400 of 649
## Documents 600 of 649
## Documents 649 of 649M <- pmApi2df(D)## ================================================================================M <- convert2df(D, dbsource = "pubmed", format = "api")##
## Converting your pubmed collection into a bibliographic dataframe
##
## ================================================================================
## Done!Now we use the following commands to get an overview of the data. This information can be gattered in a table suitable for html files. Some attributes like cell positions, cell alignment and so on can be set with different arguments of kable function.
results <- biblioAnalysis(M)Sometimes, researchers may prefer TO do their analysis in a specific type of document, as only articles. On the other hand, since Rstudio company have been found in 2011, searches are limited to after 2011.
M <- filter(M, M$DT == "JOURNAL ARTICLE" & M$PY >= 2011)
results <- biblioAnalysis(M)a <- summary(results)knitr::kable(a$MainInformationDF, caption = "Main information of articles",align = "llccl", format = "html") %>%
kable_classic(full_width = F, position = "center")| Description | Results |
|---|---|
| MAIN INFORMATION ABOUT DATA | |
| Timespan | 2011:2022 |
| Sources (Journals, Books, etc) | 410 |
| Documents | 606 |
| Annual Growth Rate % | 36.77 |
| Document Average Age | 2.53 |
| Average citations per doc | 0 |
| Average citations per year per doc | 0 |
| References | 1 |
| DOCUMENT TYPES | |
| journal article | 606 |
| DOCUMENT CONTENTS | |
| Keywords Plus (ID) | 1420 |
| Author’s Keywords (DE) | 1933 |
| AUTHORS | |
| Authors | 3156 |
| Author Appearances | 3596 |
| Authors of single-authored docs | 22 |
| AUTHORS COLLABORATION | |
| Single-authored docs | 23 |
| Documents per Author | 0.192 |
| Co-Authors per Doc | 5.93 |
| International co-authorships % | 0 |
General information about scientific documents
Here, we can look at some tables and plots which are distracted from data set based on our search strategy.
Scientific documents production year by year
knitr::kable(a$AnnualProduction, caption =
"Annualy Production for scientific Documents",
align = "cc", format = "html") %>%
kable_classic(full_width = F, position = "center")| Year | Articles |
|---|---|
| 2011 | 3 |
| 2012 | 6 |
| 2013 | 4 |
| 2014 | 21 |
| 2015 | 19 |
| 2016 | 24 |
| 2017 | 35 |
| 2018 | 34 |
| 2019 | 72 |
| 2020 | 139 |
| 2021 | 155 |
| 2022 | 94 |
Based on this table, it seems that number of published documents has increased in recent years. Maybe because of Covid-19 pandemi.
Top 10 most cited papers of PubMed papers analyzed by Rstudio
knitr::kable(a$MostCitedPapers[,1:2], caption = "10 Most Cited Papers",
align = "ll",format = "html") %>%
kable_classic(full_width = F, position = "center")| Paper | DOI |
|---|---|
| LIU Y, 2022, FRONT CELL DEV BIOL | 10.3389/fcell.2022.946363 |
| CAI Z, 2022, ENVIRON HEALTH PREV MED | 10.1265/ehpm.22-00023 |
| ALKHAYYAT S, 2022, MEDICINE (BALTIMORE) | 10.1097/MD.0000000000030576 |
| WANG Z, 2022, J ONCOL | 10.1155/2022/5300523 |
| DA SILVA TORRES MK, 2022, FRONT CELL INFECT MICROBIOL | 10.3389/fcimb.2022.932563 |
| PRIMATIKA RA, 2022, VET WORLD | 10.14202/vetworld.2022.1814-1820 |
| CUI QQ, 2022, MEDICINE (BALTIMORE) | 10.1097/MD.0000000000030728 |
| PADAR C, 2022, CUREUS | 10.7759/cureus.28414 |
| HUANG X, 2022, HEMATOLOGY | 10.1080/16078454.2022.2127462 |
| YENEW C, 2021, ITAL J FOOD SAF | 10.4081/ijfs.2022.10221 |
10 most cited papers are seen in the following table.
Top 10 journals in of PubMed papers analyzed by Rstudio
Here, we can see top 10 journals based on their frequency of published documents. Apparently, PLOS ONE and BIOINFORMATICS are prominent in this field.
knitr::kable(a$MostRelSources, caption = "Top 10 Journals", align =
"lc", format = "html") %>% kable_classic(full_width = F, position = "center")| Sources | Articles |
|---|---|
| PLOS ONE | 21 |
| BIOINFORMATICS (OXFORD ENGLAND) | 20 |
| METHODS IN MOLECULAR BIOLOGY (CLIFTON N.J.) | 11 |
| BMC BIOINFORMATICS | 8 |
| F1000RESEARCH | 8 |
| BIOMED RESEARCH INTERNATIONAL | 7 |
| CUREUS | 7 |
| INTERNATIONAL JOURNAL OF ENVIRONMENTAL RESEARCH AND PUBLIC HEALTH | 7 |
| MEDICINE | 7 |
| DATA IN BRIEF | 6 |
Top 10 keywords: DE and ID of PubMed papers analyzed by Rstudio
Here, we can see top 10 keywords based on their frequency of published documents. important We should notice that there are two types of keywords which we investigate them separately. DEs are keywords extracted from article. IDs are keywords of references of articles.
knitr::kable(a$MostRelKeywords, caption = "Top 10 Keywords", align = "lclc", format = "html") %>%
add_footnote(c("DE: Keywords Extracted from Articles","ID: Keywords
Extracted from References of Articles"), notation="alphabet") %>%
kable_classic(position = "center")| Author Keywords (DE) | Articles | Keywords-Plus (ID) | Articles |
|---|---|---|---|
| COVID-19 | 20 | HUMANS | 320 |
| META-ANALYSIS | 19 | FEMALE | 91 |
| R PROGRAMMING LANGUAGE | 18 | MALE | 85 |
| R | 17 | SOFTWARE | 82 |
| RSTUDIO | 16 | ADULT | 54 |
| PROGNOSIS | 14 | MIDDLE AGED | 47 |
| BIOINFORMATICS | 11 | COMPUTATIONAL BIOLOGY | 43 |
| MACHINE LEARNING | 11 | AGED | 41 |
| CANCER | 10 | ANIMALS | 37 |
| SARS-COV-2 | 9 | RETROSPECTIVE STUDIES | 37 |
| a DE: Keywords Extracted from Articles | |||
|
b ID: Keywords Extracted from References of Articles |
Top 10 authors and their timeline production
res <- authorProdOverTime(M, k=10)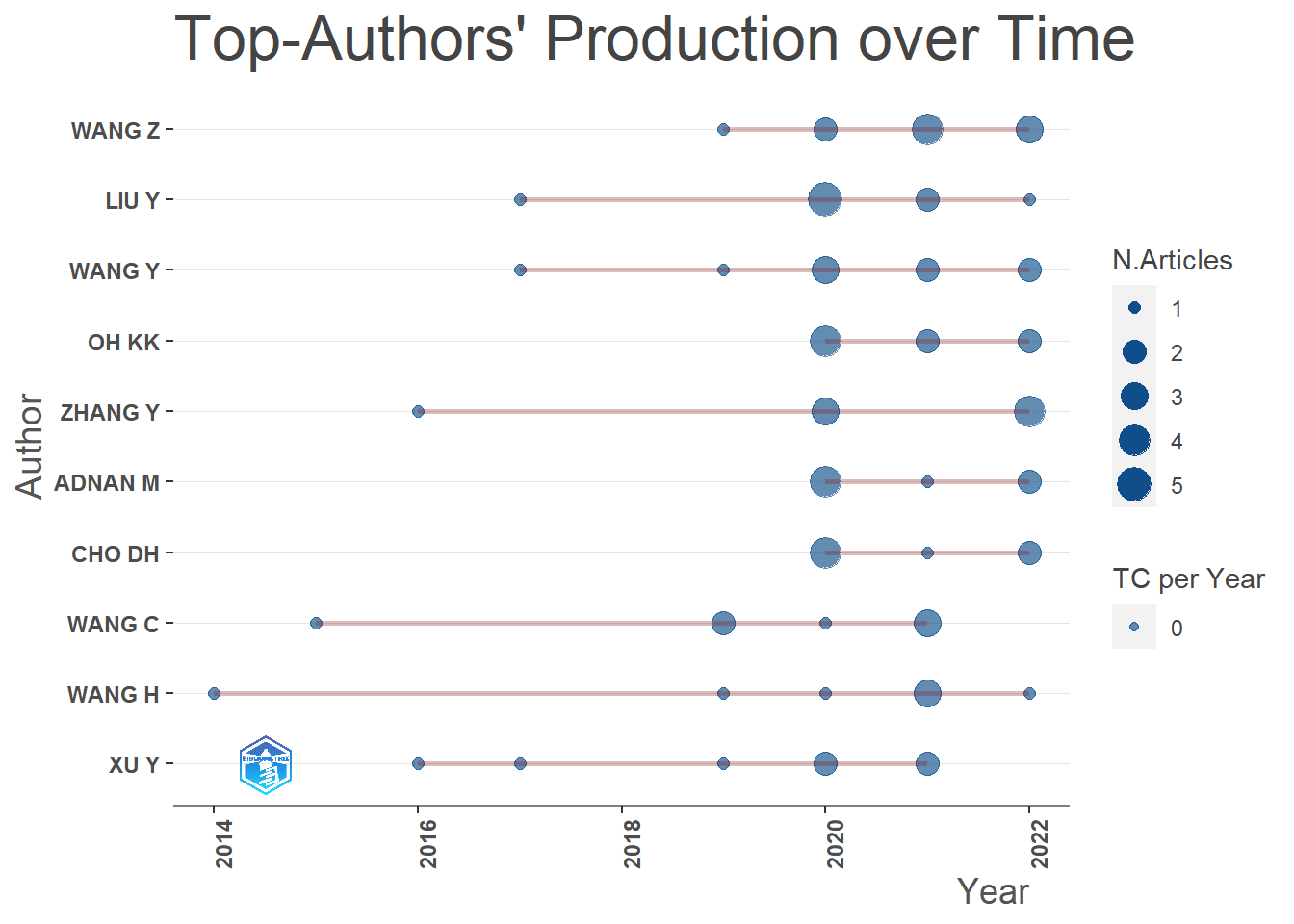
knitr::kable(res$dfAU[1:3], caption = "Top 10 authors and their timeline,as well annually production, total citations, total citations per year", format = "html") %>% kable_classic(position = "center")| Author | year | freq |
|---|---|---|
| ADNAN M | 2020 | 4 |
| ADNAN M | 2021 | 1 |
| ADNAN M | 2022 | 2 |
| CHO DH | 2020 | 4 |
| CHO DH | 2021 | 1 |
| CHO DH | 2022 | 2 |
| LIU Y | 2017 | 1 |
| LIU Y | 2020 | 5 |
| LIU Y | 2021 | 2 |
| LIU Y | 2022 | 1 |
| OH KK | 2020 | 4 |
| OH KK | 2021 | 2 |
| OH KK | 2022 | 2 |
| WANG C | 2015 | 1 |
| WANG C | 2019 | 2 |
| WANG C | 2020 | 1 |
| WANG C | 2021 | 3 |
| WANG H | 2014 | 1 |
| WANG H | 2019 | 1 |
| WANG H | 2020 | 1 |
| WANG H | 2021 | 3 |
| WANG H | 2022 | 1 |
| WANG Y | 2017 | 1 |
| WANG Y | 2019 | 1 |
| WANG Y | 2020 | 3 |
| WANG Y | 2021 | 2 |
| WANG Y | 2022 | 2 |
| WANG Z | 2019 | 1 |
| WANG Z | 2020 | 2 |
| WANG Z | 2021 | 4 |
| WANG Z | 2022 | 3 |
| XU Y | 2016 | 1 |
| XU Y | 2017 | 1 |
| XU Y | 2019 | 1 |
| XU Y | 2020 | 2 |
| XU Y | 2021 | 2 |
| ZHANG Y | 2016 | 1 |
| ZHANG Y | 2020 | 3 |
| ZHANG Y | 2022 | 4 |
Timeline production of best journal of PubMed papers analyzed by Rstudio
topSO = sourceGrowth(M, top=1, cdf=FALSE)
DF = melt(topSO, id='Year')
ggplot(DF,aes(Year,value, group=variable, color=variable))+geom_line()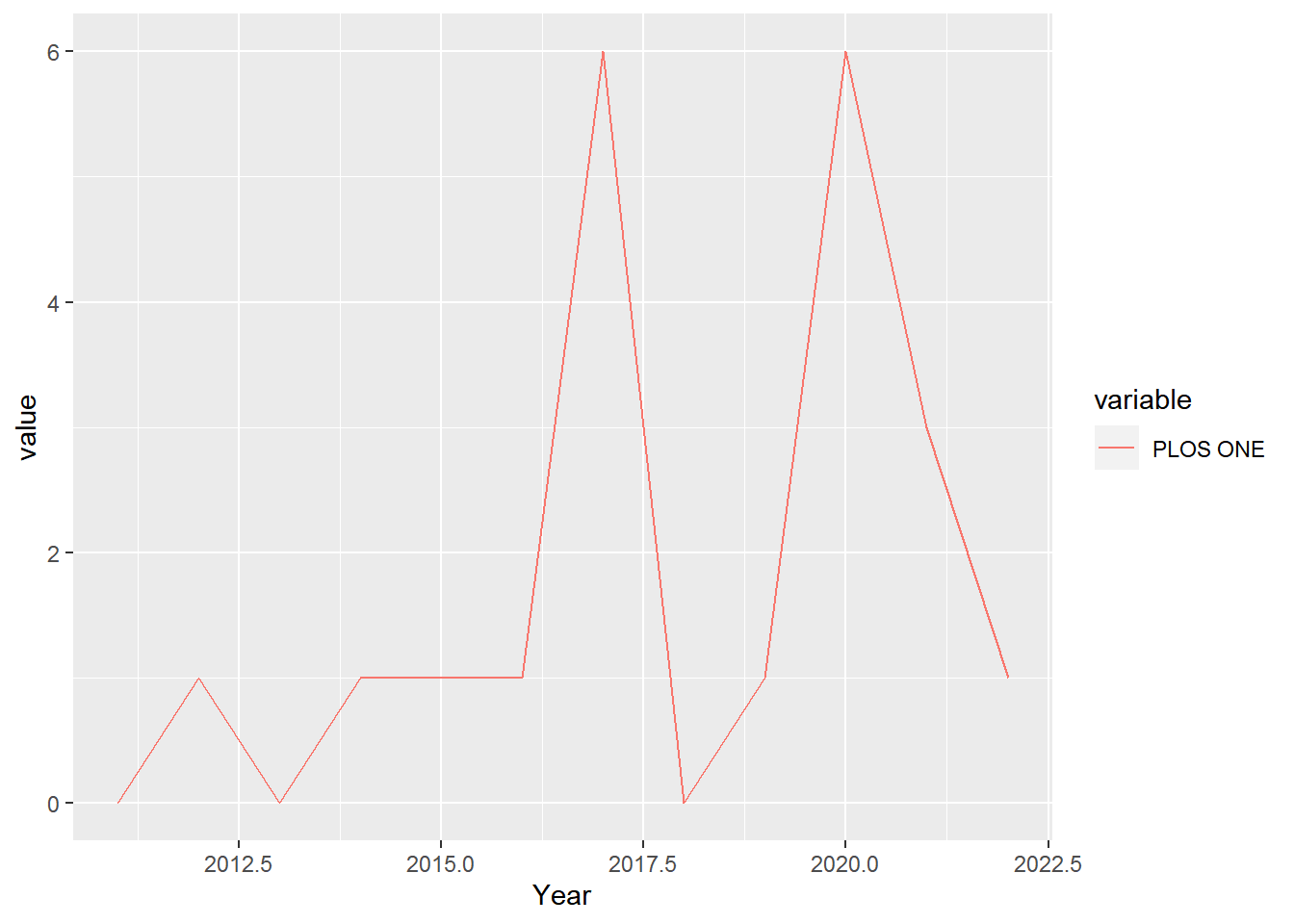
topSO = sourceGrowth(M, top=3, cdf=FALSE)
DF = melt(topSO, id='Year')Top countries based on frequency of publications in their journals
knitr::kable(head(sort(table(M$SO_CO),decreasing=TRUE),10), caption = "Top Countries based on Frequency of published articles in Journals", col.names = c("Country", "Frequency"), align = "lc", format = "html") %>%
kable_classic(full_width = F, position = "center" )| Country | Frequency |
|---|---|
| UNITED STATES | 199 |
| ENGLAND | 168 |
| SWITZERLAND | 81 |
| NETHERLANDS | 43 |
| GERMANY | 14 |
| CANADA | 13 |
| CHINA | 10 |
| BRAZIL | 7 |
| GREECE | 7 |
| NEW ZEALAND | 7 |
As can be seen, United states and England are two prominent countries based on publishing articles.
What does say Lotka’s Law us about these data set?
L=lotka(results)
lotkaTable=cbind(L$AuthorProd[,1],L$AuthorProd[,2],L$AuthorProd[,3],L$fitted)
knitr::kable(lotkaTable, caption = "Frequency Of Authors Based on Lotka's Law", digits = 3, align = "cccc", format = "html",col.names = c("Number of article", "Number of authors", "Frequency based on data", "Frequency based on Lotka's law")) %>%
kable_classic(full_width = F, position = "center")| Number of article | Number of authors | Frequency based on data | Frequency based on Lotka’s law |
|---|---|---|---|
| 1 | 2893 | 0.917 | 0.626 |
| 2 | 180 | 0.057 | 0.064 |
| 3 | 48 | 0.015 | 0.017 |
| 4 | 12 | 0.004 | 0.007 |
| 5 | 7 | 0.002 | 0.003 |
| 6 | 5 | 0.002 | 0.002 |
| 7 | 6 | 0.002 | 0.001 |
| 8 | 2 | 0.001 | 0.001 |
| 9 | 2 | 0.001 | 0.000 |
| 10 | 1 | 0.000 | 0.000 |
Pvalue of two-sample Kolmogorov-Smirnov test between the frequency based on data and the Lotka’s Law is 0.0148932. In significance level of 0.05, this value says us that our data do not follow Lotka’s law.
Collaboration networks for authors
Collaboration network of authors are plotted. As well, the network can be plotted for keywords, universities and countries.
NetMatrix <- biblioNetwork(M, analysis = "collaboration",
network = "authors", sep = ";")
net <- networkPlot(NetMatrix, n = 10, type = "auto", Title = "collaboration Network",labelsize=1, halo = TRUE) 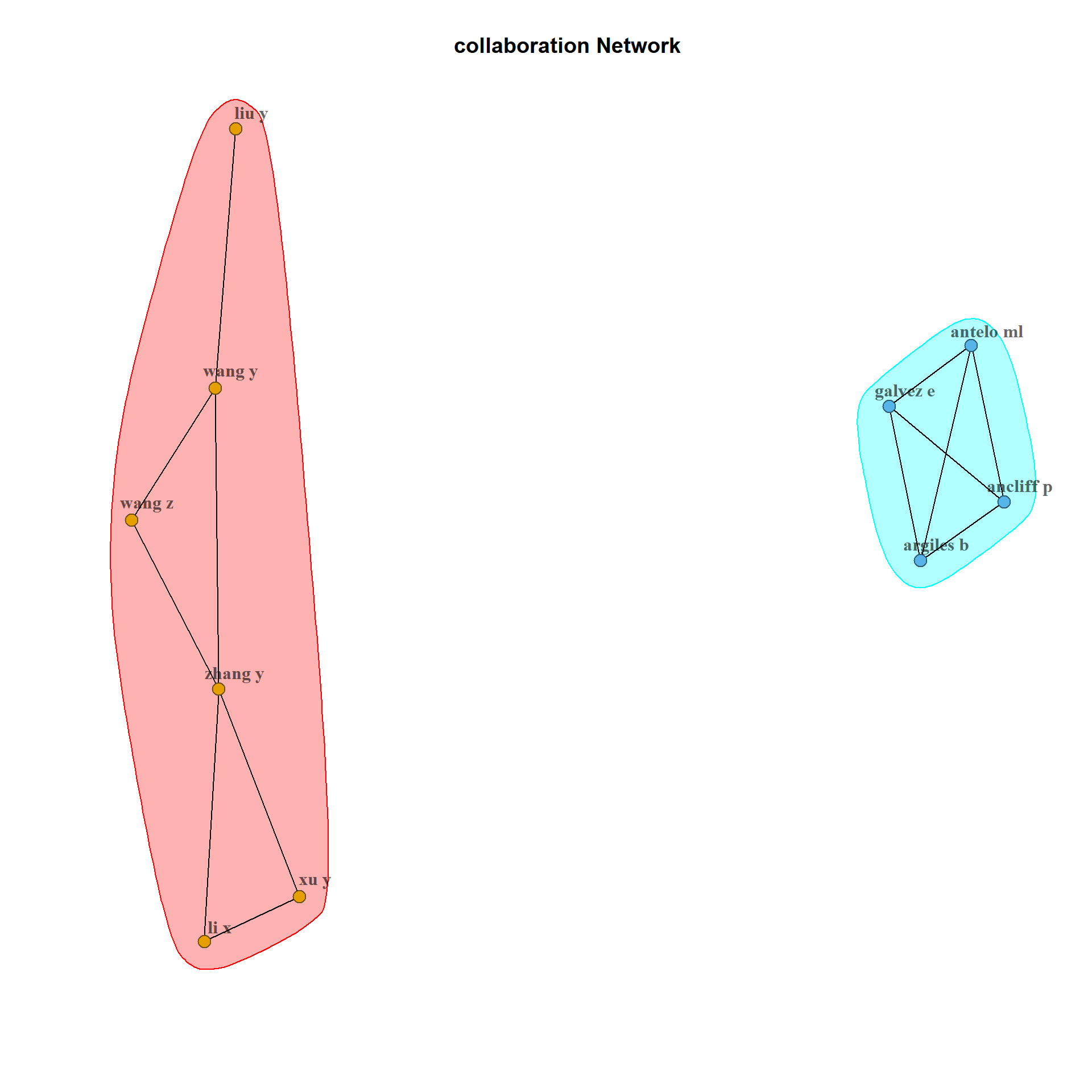
Thematic map
Thematic Maps are plotted based on (keywords) DE AS follows:
remove.terms.1word = c("aged","map","allergy","demand","rest","workflow","data collection","r","rstudio","data analysis","conservation","review","functional",
"clinical","identification","data","analysis","network","systematic","r programming","r package","maternal","reproducibility","r language","methods","treatment","r programming language","sars-cov-2","retention","calcium","statistics","open source","quality","methodology","complications","statistical analysis","prognosis","algorithms","software")
synonyms1 <- c("covid-19;coronavirus","gene; genes", "prediction; predicting", "modeling; modelling; resting","emotion; emotional", "adhd; hyperactivity",
"differentially expressed genes;differentially expressed")
tm1 = thematicMap(M, field = "DE",n.labels = 2, ngrams = 1, remove.terms = remove.terms.1word,synonyms = synonyms1)
plot(tm1$map)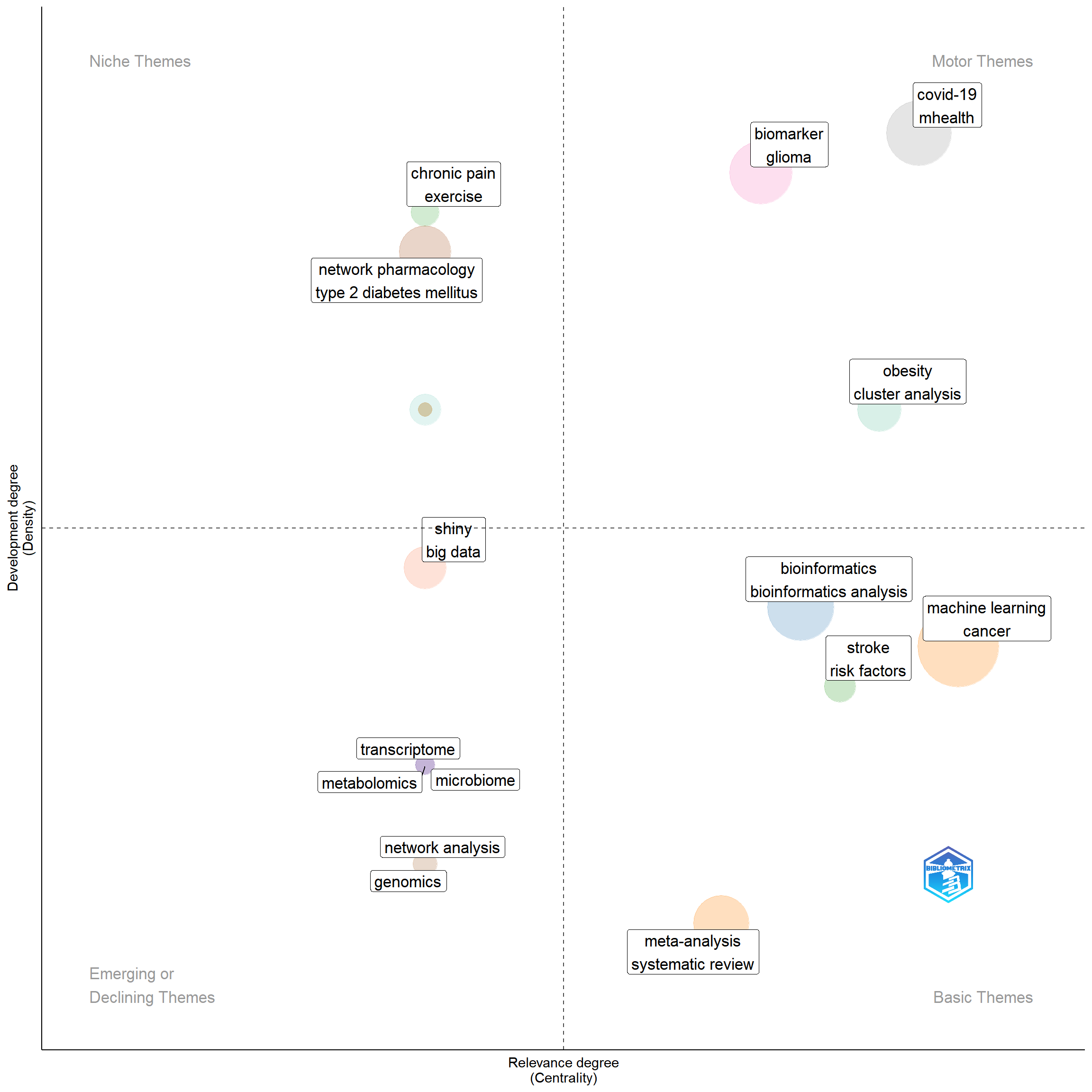
Thematic map is a plot which has been divided to four quadrant: Niche Themes, Motor Themes, Basic Themes and Emerging or declining Themes. For more details refer to (Zhang et al. 2022).
Motor Themes: Quadrant I, located in the upper-right quadrant, named motor
themes, suggested that the themes of the quadrant have developed
and formed important pillars that shape the field of research.
Niche Themes: Quadrant II, located in the upper left quadrant, named niche themes, reflected highly developed but isolated themes.
Emerging or declining Themes: Quadrant III, located in the lower-left
quadrant and named emerging or declining themes, suggested weak development and marginalization of the research field.
Basic Themes: Quadrant IV, located in the lower-right quadrant, was named as basic themes. Although these topics are less developed, they are important to the field of study.
Some diseases (motor themes), like obesity, covid_19, schizophernia, cancer, tuberculosis are discussed well and highly developed and analyzed by Rstudio. on the other side, some statistical and analytical topics such as machine learning, pca (principal component analysis), bibliometrics and bioinformatic analysis.
some diseases (basic themes) like type 2 diabetes mellitus, stroke, differentially expressed genes need to be considered and analyzed more than the present by rstudio, as well as meta analysis, systematic review, network analysis and computational analysis are methods which is reccommedned to use.
Based on this map, there are some themes which have been over discussed (topics covered by niche themes quadrant) in PubMed database. Topics such as, natural language processing, text mining, Pan-Cancer, behavioral science etc. As well, themes in quadrant lll, for example visualization and shiny are of declining themes.
Explanation: some words which we don’t want to be included in the map, as well synonym words are predefined.
Associations among our information
Here, we can see association among Authors, DEs and Journals.
threeFieldsPlot(M)This plot shows how keywords, authors and journals are related to each other.
Thematic Evolution Plot
Here, We can See Evolution of Topics in RStudio applications field based on DE and TI.
This plot shows themes which have been evolutted during the years.
years=c(2019)
nexus <- thematicEvolution(M,field="DE",years=years,n=100,
minFreq=3, ngrams = 1,remove.terms = remove.terms.1word,
synonyms = synonyms1)
plotThematicEvolution(nexus$Nodes,nexus$Edges)nexus <- thematicEvolution(M,field="TI",years=years,n=100,
minFreq=3, ngrams = 2,remove.terms = remove.terms.1word,
synonyms = synonyms1)## Warning: Expected 2 pieces. Missing pieces filled with `NA` in 1 rows [779].plotThematicEvolution(nexus$Nodes,nexus$Edges)References:
- Posted on:
- October 16, 2022
- Length:
- 11 minute read, 2311 words